最近有需要用到文字辨識,上網找到了JOCR這個軟體,這是一套Freeware,是EverRex Software的產品。下載後不用安裝,直接執行即可使用,目前版本JOCR 1.0(March 13, 2006),只有84KB。
官方網站:http://home.megapass.co.kr/~woosjung/index.html
下載網址:http://home.megapass.co.kr/~woosjung/Index_Download.html
開啟JOCR.exe,使用抓取功能(Capture Region、Desktop、Windows),擷取螢幕上的文字(通常是圖上的文字)。記得要先選取視窗最下方的語言,例如「Chinese_traditional」,才能正確辨識想要的文字。
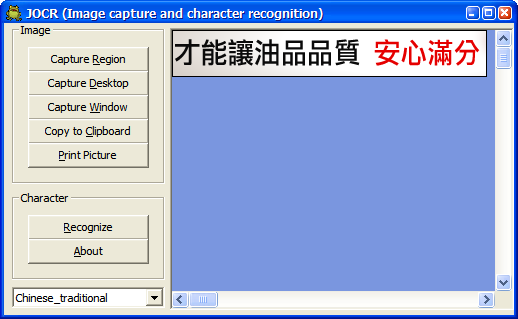
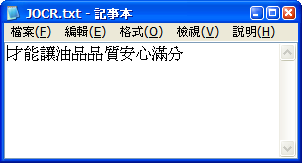
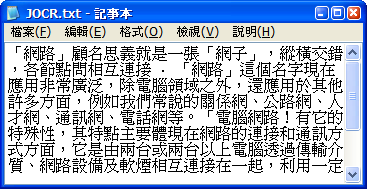
當按下「Recognize」按鈕,即會執行辨識工作,不一會兒,辨識好的文字,會在記事本中顯示。
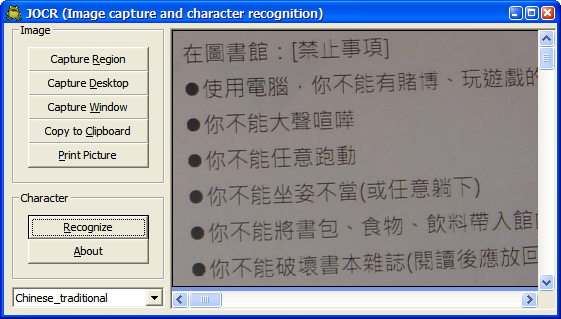
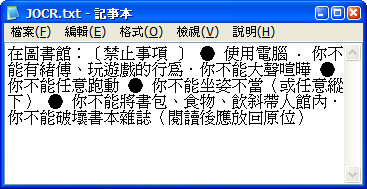
再拿一份文件以掃描器掃描後顯示在畫面上,然後抓取想要部分的畫面(因為無法開啟檔案,只能抓取畫面)。再按下「Recognize」按鈕,顯示的結果,發現辨識率真的不差。而文字歪歪的,也能接受。尤其又是免費的,實在是個小而美的好用工具。


試著拿數位相機來拍文件,讓JOCR來辨識看看:

抓取螢幕上的片段,雖然有些暗,沒有加以影像處理,直接來讓它辨識。
結果也是令人滿意哦!
利用google圖書來搜尋書本。
抓取想要的文字(字體不要太小):
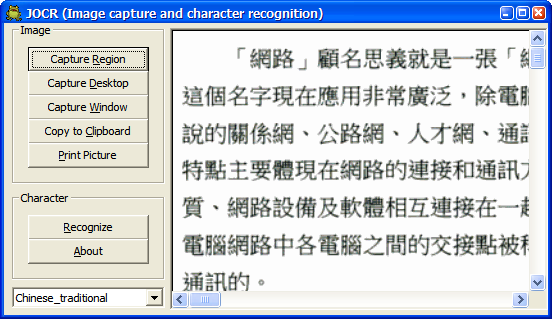
辨識效果一樣完美。





請先 登入 以發表留言。